Coppell Technologies
Coppell Technologies
スマートシティの標準規格
Menu
Coppell Technologies (Top)
Fiwareで都市OSを動かしてみよう
NGSI-LDにも挑戦
データ仕様の現状と課題
スマートシティの標準規格
データモデルのユースケース
Column
Link集
用語集
Coppell Technologies (Top)
Fiwareで都市OSを動かしてみよう
NGSI-LDにも挑戦
データ仕様の現状と課題
スマートシティの標準規格
データモデルのユースケース
Column
Link集
用語集
Coppell
Technologies
4. 語彙 (共通パーツ)
| 2022-09-29/2023-02-10 スマートシティに実際にサービスを実装する各種業界の視点でいうと、権限を持つ公的機関や権威ある標準化団体が策定した網羅的な「標準語彙」というべきものはありません。これは恐らく語彙という無限の広がりを持つとともに、業界や専門分野毎に方言とか専門用語と言うべきものが多数存在する点に加え、年々歳々変化し続ける性質によるものだと思われます。この難敵に対し、グローバルにはschema.orgなどのコミュニティーが存在し、ほぼデファクトスタンダードの地位を占めつつ、日々更新されていくコミュニティー活動があります。国内では、今年3月にデジ庁のGIFに統合されたIMIのコア語彙というものがあり、共通的な語彙を抽出して「コア語彙」を策定する事で、実際に業務で使用する「ドメイン語彙」を民間含めて効率よく策定できる土台を整えています。 後の章で詳しく述べますが、当面のスマートシティの活動ではNGSI v2のインタフェースで活用する事になります。NGSI v2を前提とする場合、デジタル庁のコア語彙は幾つか課題があります。例えば、自由度が大きすぎて、利用者が個々にデータモデルを策定すると、突合が難しくなってしまいます。また、NGSIではData Model名(Entity type)やAttribute名(Attribute name)も統一する必要がありますが、コア語彙ではそこまで定義していません。そこで、コア語彙、およびschema.orgを継承して、NGSI V2準拠を前提としたドメイン語彙を策定する事が必要です。ドメイン語彙の考え方はコア語彙に書かれていますので、興味があれば参照してください。 スマートシティでは、データはクロスドメインで活用する事が前提なので、「ドメイン」という用語で誤解を招く可能性があります。更に言うと、NGSI V2に特化して事細かに規定したものを「語彙」と称して良いのかについても疑問があります。そこで、本書では語彙と言う用語は避けて、共通パーツと呼ぶことにします。
以下、参考のためにGIF等の説明を記載します。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2022年8月13日 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 政府相互運用性フレームワーク(GIF: Government Interoperability Framework)が、2022年3月にデジタル庁から発表されました。データの整備やデータ交換のフレームワークとの事ですが、現在の版はデジタル庁発足前に各省庁に分散していた各種の規約を集めたもので、2023年には改版される予定との事です。コア語彙は、現在の版でGIFを構成するものの一つとして位置づけられています。 現在のコア語彙は、情報共有基盤 -- IMI(Infrastructure for Multilayer Interoperabilit)のサイトに収録されていて、誰でも見る事ができます。IMIは共通語彙基盤と文字情報基盤に分かれており、共通語彙基盤は更に共通語彙とDMDに分かれ、共通語彙はまた更にコア語彙とドメイン語彙に分かれています。コア語彙は、「幅広い業務分野に共通する、基本的な語彙」であるとされかなり限定された語彙だけが収録されています。この点で、後で出てくくるschema.orgなどとは考え方が異なっている様です。 「語彙」は英語ではVocabularyと言いますが、用語の定義です。用語の定義と言っても良く分からないと思いますので、実物を見てみましょう。下図は「氏名」というものの定義です。「氏名」という情報には、「姓」や「名」という属性情報が含まれると言う意味です。他にもカナやローマ字の属性などもありますね。 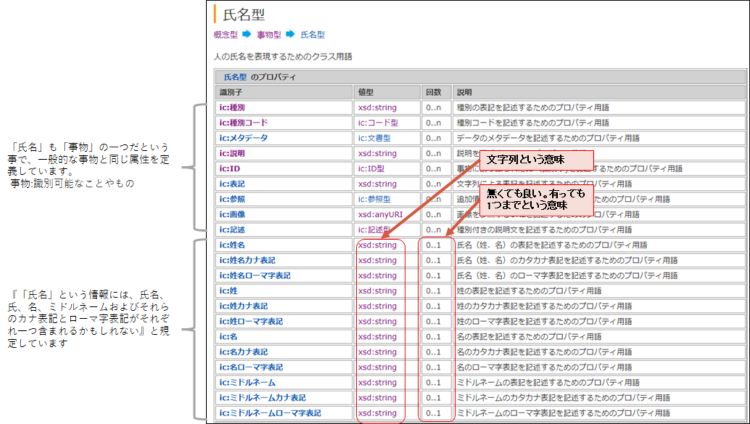 後の章でデータモデルが出てきますが、策定したいデータモデルの中に氏名情報も入れたい場合、「回数」の指定に従いながら、値型を拾っていく事で、データモデルを設計する事が出来ます。尚、コア語彙は項目名を決めるものではありませんし、「回数」を見ても分かる様に自由度も高いため、詳細はデータモデルの設計時に決めていきます。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2022年8月13日 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GIFにはドメイン語彙は含まれておらず、またIMIも管理しないし登録も不要となっています。このため、浅学な筆者の知る範囲では、ドメイン語彙その存在を認識していません。 但し、今後スマートシティの実装を進めていくにあたり、オープンな環境下で議論/策定され、IRIの情報も含めて公開され、柔軟に改版されていくドメイン語彙の策定は必須となると考えられる。筆者の勝手な意見ではあるが、柔軟性を確保し、既存の規定類に忖度しない必要があることから、できれば政府からは独立性が高いコミュニティーで運営されることが望ましいと考えます。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
2022年8月13日 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| グローバルには語彙は多数定義され、活用されています。また、日本のコア語彙の様に厳密に語彙の範囲を限定しておらず、データモデルと言うべき定義も含まれています。日本のコア語彙では氏名などのクラスの定義はありますが、個々のプロパティの名称は決められていませんが、グローバルには名称や項目の値に許される値(列挙型メンバ)なども決める事で自由度を下げてデータ交換を容易にしているようです。コア語彙と最も大きな違いは国による制定ではなくコミュニティーによる制定である事です。従って、語彙間で違いはあり得ますし、同じ用語の定義が違う内容である事もあり得ます。利用する側が選択し、使われない語彙は淘汰され、全体として進化していく事になります。 想像してみて下さい。例えば政府の各種統計を見ると性別は男女の二つです。これに対し、ISO標準では不明、男性、女性、適用不能の4種類です。政府がコア語彙で「性別」の値の列挙型メンバを決めるとき男女だけにするでしょうか、それともISOの様な4種類にするでしょうか。それともLGBTQまで分けてもっと多数の選択肢を用意するでしょうか。それだけで政治論争になりそうです。民間であれば、語彙が並立して使う側が選択して淘汰していくだけですよね。
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

