Coppell Technologies データ仕様の現状と課題
1. データ交換の基礎
|
|
2022-07-12 |
スマートシティとは、ICT技術面から見るとIoT(Internet of Things)の技術を基盤とした、システムとシステムが相互につながりあってデータを交換して価値を創造する世界です。IoTというと、センサをクラウドに繋いで何やら自動化するというイメージがありますが、本質的にはセンサだけでなくコンピューター同士も人間を介さずに繋がります。この、「人間を介さず」という部分が大事なのですが、人間介さずにコンピューター間でデータ交換するためには、コンピューター間で非常に沢山の取り決めを事前に行う必要があります。本書では、このコンピューター間のデータ交換に焦点を当てて、調査を進めていきます。
スマートシティにおけるシステム間のデータ交換は、多くの場合独立したシステムやデバイスの間でのデータ交換となります。つまり、ある程度距離があるシステム間のデータ交換となる訳です。また、1対1のデータ交換とは限らず、N対Mの不特定多数の参加者によるデータ交換となる場合もあります。このため、既に不特定多数間のデータ交換の手段であるインターネットの技術を用いてデータ交換を行います。
実は、この種のデータ交換は昔からからあります。たとえば、コンビニにあるATMを使うと、自分の口座がある銀行から預金を引き出せます。これは、ATMがキャッシュカードを読み取って、口座番号などを把握し、利用者が入力したパスワードや金額の情報を銀行に送ることにより取引が成立します。ATMを設置している会社と銀行は多くの場合別の会社ですから、別の会社の別のシステム間でデータがやり取りされたことになります。この他に、クレジットカードによる店頭決済、無数にあるスマフォのアプリなど全てデータを交換する事により業務が成立しています。昔からあったと言っても、以前は高価なシステムだったので、気軽に使えるものではありませんでした。それが、インターネット技術の進化と普及に伴って価格が低下し、今は誰でも使える様な技術になってきたのです。
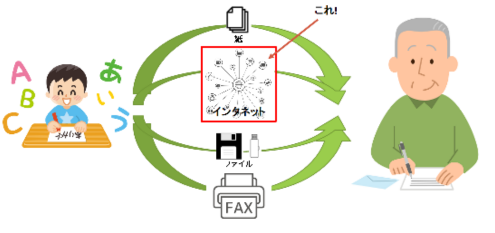
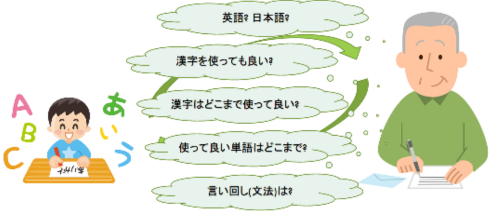
インタネットのデータ交換というと、思い浮かぶのはWebやメールだと思いますが、これらの技術は文字を組み合わせた「文」を相互に送りあう事により実現しています。文で物事を伝えるのですから、ちょうど子供との手紙のやり取りに例える事が出来ます。文と言っても日本語なのか英語なのかフランス語なのか。日本語だとすると漢字を使って良いのか。漢字を使って良いにしても、子供が知っている範囲の漢字でないと、手紙は読めません。漢字が読めても単語の意味が分からないかもしれません。単語は分かっても、平易な文法で書かないと、子供は意味が分からないかもしれません。コンピューター間のデータ交換でも、この様な多くの取り決めを事前に行う必要があるのです。
|
|
「データ交換」「データ連携」という用語: データ連携やデータ交換という用語は色々なところで用いられています。ところが、必ずしも本書で記述する様な意味で用いていない場合もあります。本書では、インターネットの技術、つまり暗黙的にデータを送る仕組みが備わっている事を前提としていますが、データの集配信についても同じ用語が用いられています。特に自治体や政府はExcelやcsvでデータを送りあう業務が多く、それらもデータ交換やデータ連携と呼んでいます。混乱すると思いますので、データ交換やデータ連携と言う用語が出てきたときは、どちらの意味か意識する必要があります。 |
この他に、例えば以下の取り決めが必要な場合があります。
- センサデータなどの場合、タイミング、頻度、鮮度、採取環境などの要件
- 同様に、センサデータに採取したタイミングなどのメタデータを付加する事の要否
- 公開の範囲 (個人情報への抵触の回避など)
|
|
余談: 現在、文字セットの標準はUnicodeであり、JIS標準に掲載されている日本で使うで全ての文字は登録済みという事になっています。ただ、パソコンやプリンタのフォントが全ての文字に対応しているとは限りません。筆者の友人で、マイナンバーカードに印刷されている名前の文字が、戸籍と一致しないからマイナンバーカードを停止するとの通知を自治体から貰ってとても困ったという例がありました。 |
|
|
|
2022-07-12/2023-11-20 |
2022年3月31日にデジタル庁から政府相互運用性フレームワーク (GIF: Government Interoperability Framework) が発表されました。GIFは政府機関や自治体がデータ交換をする際の取り決めやガイドラインの集大成です。GIFは必ず守るべき標準ではなく、参照モデルであるとの説明があり、また政府の各機関が対象なので、必ずしもスマートシティでの準拠を強制するものではないようです。しかし、国内にGIFに比肩する標準的なものはなく、スマートシティの重要なプレーヤーである自治体がGIFを活用するであろう事を考えると、スマートシティの民間側のプレーヤーもGIFを尊重する事が合理的であると考えています。
スマートシティの構築を考ええた場合、このGIFを参照すべきであると共に、既にデファクトの地位を固めつつあるNGSIという標準があり、NGSIとGIFとの間に矛盾が発生しない様に実装していく事もまた、重要となります。本資料では、関係する各種標準を調べて、どこが矛盾し、どこが不足しているのかなどについ調査していきます。
前節では、コンピューター同士が文字を使ったデータ交換をする場合に、何をとり決めておく必要があるのかを整理しました。本節では、GIFの関係を整理します。下表では、前節の表に対する対応関係を整理しました。
| 分類 |
GIFにおける記述 |
| 文字セット |
実践ガイドブックの文字環境導入実践ガイドブックに記述があります。記述によると、文字情報基盤の6万字の内、JIS X 0213の約1万文字の利用を強く推奨しています。
インタネットではUnicodeという文字セットがデファクトスタンダードなのですが、JIS X 0213は、2002年に制定されたUnicode 3.2に反映されています。従って、現在はUnicodeを採用する事はJIS X 0213に準拠する事を意味しますので、インタネットの標準であるUnicodeを採用すればGIFとも整合します。 |
| 符号化方式 |
GIFには記述が無いと思います。従って、現在のインタネットのデファクトスタンダードであるUTF-8を採用しても、GIFとは整合します。尚、ベースレジストリのデータや政府のホームページを幾つか拾って確認しましたが、全てUTF-8になっていましたので、日本でも既にUTF-8がデファクトスタンダートになっているようです。 |
| 語彙 |
GIFの「コア語彙」が対応します。コア語彙は文字通り「コア」となる語彙であり、実際に活用する際にはドメイン語彙と呼ばれる語彙を追加策定する必要があります。また、コア語彙にはデータの表現方法に多くの選択肢が提示されており、それらの選択肢からどれを選択するか個々に取り決める必要があります。例えば、住所では、国を国名とするか国コードとするか、或いは省略するかを取り決める必要があります。また、形式を策定する必要もあります。例えば、コア語彙の地理座標は一見すると緯度と経度を別の項目で記述する様に見受けられますが、GeoJsonという標準ではひとつの項目に二つの値を並べて入れる事になっているので、その様に形式を変換するなどの検討が必要です。尚、同じデジタル庁が推奨するデータ連携基盤のデータ仲介機能のプログラムはGeoJsonを前提に作成されています。 |
| 情報モデル |
GIFには特に記述はありません。但し、コア語彙、コアデータモデル、標準データセットなどを参照すると、基本的にはフラット形式、つまり表形式を想定している様に思われます。フラット型式は、二階層モデルとかカラム形式とか記述している記述も散見されますが、皆さんご存知のExcelなどの表計算ソフトの表だと理解して頂ければ正しいです。また、配列や構造化されたデータについても統一した考え方は無く、個別に策定している様に見受けられます。NGSI V2やNGSI-LDは三階層や不定階層なので、どの様に整合させるかは検討が必要です。 |
| データ形式 |
GIFには特に記述はありません。また、7月にデータ社会推進協議会から発表された、デジタル庁が進める「推奨モジュール」では、現時点ではJSON対応のモジュールしか発表されていません。一方、インタネットでは、JSONやJSON-LDという形式が採用されている場合が多いで、JSONを採用する事でGIFと整合する事は可能です。但し、NGSI最新規格はNGSI-LDであり、データ形式はJSON-LDなので、ひとつ前のデータ形式であるJSONを採用しても良いのかどうか、検討が必要です。 |
| データモデル |
データモデル名 |
特に規定は無いように思われます。また、コア・データモデルを見ると、データ内にデータモデルを区別するための情報も入っていない様に思われます。尚、自治体共通オープンデータセットにはデータセット名はあります。例えば「××一覧」の様なものです。従って、データセット名を個々のデータのモデルを表すデータモデル名として流用する事は難しいように思われます。 |
| データ構造 |
コア・データモデル等の記述があります。但し、一部ですが、「備考」に自然言語で記述すると規定している箇所などがあり、コンピュータ同士でデータ交換する場合には注意が必要な規定も入っています |
| データ間の関係 |
GIFには特に記述はありません。データ間の関係を定義していないという事は、各データに共通の情報も各データに含まれている事を意味し、データ量の増大や保守性の低下を招いている可能性があります。逆に、データ量の増大を避けるために必要な情報が欠落してしまう可能性もあります。実際にスマートシティに応用する場合には検討が必要です |
| 項目 |
項目名 |
コアデータモデルや推奨データセットに記述があります。但し、項目名が日本語になっているため、国際標準に合うデータモデルに変換する際には何らかの工夫が必要です |
| 値 |
表記 |
数値、文字列、日付、時刻、曜日、電話番号、住所などの表現が規定されています。但し、多種類の表記法を併記している場合があり、どの表記にするか、取り決めが必要です |
| 単語 |
GIFiに特に記述はありません。ベースレジストリなどの活動と共に、何らかの共通化の取り組みが期待されます |
| コード |
GIFやGIFから参照される文書で非常に多数のコードが規定されています。但し、国内でしか通じないコードなども多く、どれを利用するかについては個々に検討が必要です。また、スマフォなどのデバイスでのデータ利用を考えると、コードを使う事の是非も検討する必要があります。
尚、グローバルには、コードの利用は国コードなどの一部に限られ、次項の列挙型メンバを利用する場合が多い様です。 |
| 列挙型メンバ |
前項同様、グローバルな規定との整合は個々に検討する必要があります。 |
|