Coppell Technologies データ仕様の現状と課題
1. データ交換の基礎 1.3節
|
2023-01-04 |
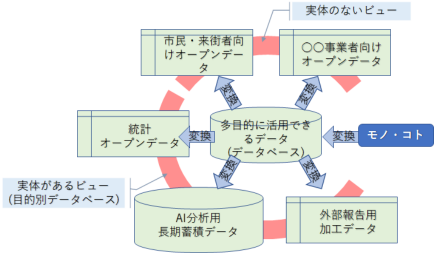
実世界のモノやコトはとても複雑ですし時間と共に変化していきます。コンピューターには実世界のモノやコトの情報の一部しか格納されていませんが、それでもそれなりに複雑です。そこで、目的に応じて簡略化したり、統計処理を施したりして、取り扱いやすい形にします。コンピューターに格納されたモノやコトのデータは一般的にはデータベースというデータの塊りで管理します。これに対し、目的別に加工したデータをビューと呼びます。ビューには実体がある場合も実体がない場合も有ります。実体がある場合でそのデータが先のデータベースとは別に管理されている場合、目的別データベースと呼ぶ場合があります。
例えば、ある自治体に住民に関するデータベースがあり、全ての住民について○○さんが転入してきた、△△さんが転出した、□□さんが生まれたなどのコトをデータとして格納してあれば、それらのデータを数え上げる事により現在の人口や10年前の年度末の人口は計算可能です。しかし、この計算は結構面倒ですし、個人情報を含むため簡単には実装できません。そこで、自治体が「現在の人口」や「2021年度末人口」というビューを実装しておけば、利用者の不便は解消されます。
ここで注意すべきことは、データベースからビューは生成できますが、ビューからデータベースを生成する事は困難である事です。前記の人口のビューをどの様に加工しても、人口の自然増減と社会増減を分離する事は出来ませんし、季節的な分析も出来ません。これは、加工や統計処理の際に情報が失われてしまうためです。このため、多目的に活用したいデータは、モノやコトをなるべくそのままにデータとして格納しておく必要があります。
更にもう一つ注意すべきことは、世の中でデータベースとかデータと呼ばれているものは、既に何かの目的に合わせて最適化されいて、モノやコトの情報の多くは失われているかもしれないと言う事です。したがって、モノやコトの全てを正確に情報として保存する事も現実的ではありません。そこで、データベースやデータの仕様はは柔軟に拡張できるようにしておき、必要に応じて現実的な範囲で拡張していくことになります。
繰り返しますが、多目的に活用するデータはモノやコトの情報をデータとして格納したものであり、ビューを格納すべきではありません。これを念頭にデータ交換の規格を調査することになります。 |
2022-04-30/2023-01-04 |
前項で記載したように、実世界のモノやコトはとても複雑ですが、コンピューターは数値や文字などしか扱う事が出来ず、モノやコトを何らかの目的や環境に合わせて最適化してデータとして格納します。筆者の経験では、だいたい以下の4種類ぐらいに分けて考えると良いように思います。上から下の向かうにしたがって、だんだん単純化が進み「人間にとっては」取り扱いやすくなりますが、その代わり元の情報が失われて行きます。
| 最適化対象 |
説明 |
モノコトに最
適化 |
現実界のモノやコトをありのままで表現しようとしているデータです。データの二次利用が期待できる一方、データ量が多くなりすぎたり、構造が複雑になるなどの弊害もあります。ICTの世界でオントロジーというと、このレベルの最適化を指すことが多い様です。昔の文書を読むと、データが多くなりすぎるのでこのレベルのデータは作るべきではないとの記述がありますが、現在はこの指摘は時代遅れだと思います。 |
団体活動に
最適化 |
データは多くの場合企業や自治体などの法人が所有しますが、法人の中で一元的にデータを管理して統合データベースなどと呼ばれるシステムを構築しようとする場合が多いです。もし一元的に管理できれば、部門間の情報共有や連携プロセスが単純化され、データ間の矛盾は発生せず、必要なデータを何時でも横串に参照できるなどのメリットはとても大きいものです。但し、実際に全ての活動を精査してどの様なデータをどの様な構造で管理する事が良いのかを設計する事は現実的には難しいですし、新たな業務が発生した場合に都度見直す必要があるなど、実際に厳密に全業務にわたって構築する事は難しく、基幹となる情報だけを統合化している場合が多い様です。
また、特定のデータについては、法令や業界標準が定められている場合もあります。これは、データ交換やセンサなどの機器の接続に有利なためです。 |
部門に最適
化 |
データを部門ごとに部門の作業プロセスにあわせて統合したものです。一般的なデータベースではこのレベルの最適化が多い様に思います。部門の権限で自由に構築できる一方、部門間にまたがるプロセスの阻害要因になったり、属人的プロセスがどうしても残存するなど、DXの阻害要因になる事もあります。一方で、部門の作業プロセスに親和性が高いため、作業効率は上がります。 |
人的作業に
最適化 |
人が作業する事を前提に、特定の業務に最適化してデータを集める場合があります。自治体標準オープンデータセットのオープンデータなどが該当します。部門間でのデータの交換にExcelを使う様な場合もこの分類です。この分類の特徴は、データが統計的な処理を施されて単純化されてしまう事が一般的という点です。例えば、「××地区のコロナの陽性者は×名で重傷者は×名、死亡者は×名」などというデータです。人が再集計するにはとても便利です。一方、一人ひとりの発症日や入院日の情報は失われていますから、後で発症日別の統計が欲しいとか、重傷者の定義を変更したいなどとなると、もうこのデータは使えません。目的や相手部門が変わるたびにExcelを作り直す必要がある事が特徴です。コンピューターはデータ量の多寡は気にしませんから、人的作業などの特定目的にデータを最適化する必要はなく、元データをそのまま共有した方が良い事が多い様です。 |
この表で上位のレベルのデータがあれば下位のこのレベルのデータに変換する事は可能な場合が多いですが、下位レベルから上位レベルのデータを生成したり、ある目的のデータを別の目的に流用したりする場合には、複数のデータをつき合わせたり追加データを収集するなど、非常に手間がかかります。良く、「オープンデータの構築には手間がかかる」などというお話を聞きますが、部門ごとにバラバラなデータや作業目的ごとのデータしかない状態で、新たな目的のデータを生成しているために過大な作業が発生しているのかもしれません。
この様に、いま保有しているデータは、あるいは作り出そうしているデータはどのレベルの最適化なのかを意識する事が大事だと感じています。つまり、前節の「多目的に活用するデータ」は、「モノコトに最適化」と「団体活動に最適化」を念頭に構築し、ビューは、「部門に最適化」や「人的作業に最適化」を念頭に構築する事になります。 |
2022-07-12 |
日常、Excel等で見かけるデータと異なり、スマートシティではコンピューター間でのデータ交換を前提にします。人間相手であれば、表やグラフの様な視認性が良いデータにすべきでしょうし、扱えるデータ量も少ないことから、ある程度データを統計的な計算により集約して、データ量を減らす必要があります。コンピュータの場合もデータ量は制約がありますが、人間に比べて桁違いに大量のデータを扱う事が出来ます。本節では、コンピュータ同士のデータ交換を前提とした場合に、どの様な最適化が可能が考えてみます。
尚、これらの最適化を進めると、結果的に「モノコトへの最適化」に近づいていく事になります。但し、やみくもに複雑化するのではなく、個々の最適化のメリットを考えながら進めていく事が大事だと考えています。
1.4.1 繰返しの表現 データの中には複数の情報を含むものがあります。例えば、"人"のデータに"あだ名"という情報も盛り込みたい場合、あだ名は複数列挙することがありえます。これをExcelやcsvの様な表形式に表現する場合は悩ましいことになります。一つのカラムに複数のあだ名を並べて記入しようか、それとも幾つかカラムを用意しておこうか等と悩むわけです。表形式は視認性が良く人間と相性が良いため、人間の作業に合わせて最適化する場合、例えば「あだ名は代表的なものひとつだけ登録する」などと規定する事になります。一方、コンピューター同士のデータ交換の場合は、表形式で表現する必要は無いため、複数のあだ名を列挙す出来るようなデータモデルを定義する事になります。
1.4.2 重複情報の排除 複数のデータに同じ情報が含まれることは良くあります。例えば、多くの自治体から公開されている「AED設置箇所一覧」というオープンデータの場合、設置している建物名と建物名のカナ表記と建物の住所がそれぞれ項目として定義されています。同じ建物に複数のAEDが設置されていると、各データに同じ内容が記載されることになります。同様に、公衆トイレ一覧を見ると、同じように設置している建物名と建物名のカナ表記と建物の住所が項目として定義されています。
これらオープンデータの場合、人間がパッと見て分かることも重要ですから、各データに同じデータが書かれていることに意味があります。一方で、建物の名称を変えた際には各データの内容をイチイチ書き換える必要が出てくるというデメリットもあります。
さて、建物情報をAED設置箇所一覧や公衆トイレ一覧から分離したらどうなるでしょうか。つまり、建物情報を独立したデータとして定義して、建物情報には建物名と建物名のカナ表記と建物の住所が項目として含まれているとします。その代わり、AED設置箇所や公衆トイレのデータの中から建物名と建物名のカナ表記と建物の住所が項目を削除して建物情報の通番の様な不変のものを保持する事にする訳です。こうすると、視認性は低下しますが、その代わり色々と良いことがあります。
- データ量が減ります。同じ値がアチコチに書き込まれませんから、データの総量が減る事になります
- データの更新が簡単になります。例えば建物の名前が東京スタジアムから味の素スタジアムに変わっても、データを一件だけ書き換えれば作業は完了です
- 建物情報に沢山の情報を格納出来ます。例えば、後から英語名やフランス語名や中国語名を追加しても、AED設置箇所一覧や公衆トイレ一覧を作り直す必要はありません。必要な情報が出てきたら、追加していけば良いという、スマートシティには都合のいい「柔軟性」が得られます
- データ間の矛盾が出にくいです。同じ情報をアチコチに格納しておくと、しばしば間違って値が相違してしまう場合があります。このリスクを回避できます
- データモデル間の名寄せが出来ます。AEDの情報と公衆トイレの情報に建物の通番を持っていれば、この通番を仲立ちにしてAEDの情報と公衆トイレの情報を名寄せできます。つまり、AEDがあって公衆トイレもある建物はどれかという事が分かります。
この様にデータモデルを分離して重複を排除する事は多くのメリットをもたらします。
1.4.3 データの管理主体ごとに分離 AED設置箇所一覧を見てみると、建物に関する情報とAEDの設置者に関する情報と設置場所の現場の連絡先などの現場情報が盛り込まれています。そうすると、このAED設置箇所一覧のデータは誰が責任もってメンテナンスするのでしょう。恐らく、自治体の職員が数年に一度関係者に聞きまわって確認するのだと思いますが、これは大変な作業です。
情報の主体毎にデータモデルを分離したらどうでしょう。責任範囲が明確になりますし、前項で記載したアチコチのデータを変更する必要も無くなりますよね。
1.4.4 データ集計の排除 新型コロナの騒ぎが始まった初期では、検査数や検査結果を集計したものが各地からがファックスで都道府県に送られてくる事が話題になりました。ファックスの場合、記載できるデータ量が限られますから、当然一日の検査の状況や結果を集計してファックスで送ることになります。都道府県や国では集まってきた集計結果を再度集計する事になります。そうすると、別の角度でデータを分析したいとか、重症度の基準を変更したいなどのニーズに対して融通が利かない事が問題視されました。
もし、あの当時スマートシティが実現できていたら、恐らく検査場の受け付けデータ、検査結果のデータ、病床のデータなどが生データとして都道府県や県に送られ(と、言うか元々共有され)て、それぞれが自由に集計する事になったと思います。
この様にデータ集計は情報の価値をそぎ落とす行為ですから、利用目的を限定したくないスマートシティにおいては最小限にとどめたいものです。 |
|
|